Ensuring compliance with mandatory medical classifications, Fujitsu’s new automatic medical coding solution extracts the annotations in typically less than 1 minute, compared to 15 minutes required for manual clinical note annotation. Unlike previous generation technologies, Fujitsu’s AI text mining technology combines semantic knowledge and Natural Language Processing (NLP) with Deep Learning in order to analyze medical notes and extract valuable data.
Fujitsu Laboratories of Europe works closely with innovation partners within the healthcare sector, including Madrid’s leading San Carlos Clinical Hospital, working on a variety of successful clinical projects in the past four years. Dr Julio Mayol, Chief Medical Officer, explains the importance of this co-creation approach from a medical perspective, “We are constantly looking for new ways of improving clinical decision-making, and our work with Fujitsu Laboratories of Europe is helping us to realize important advances to improve efficiency. Most of the EHR systems available today do not fulfil the requirements of the doctor/patient relationship. In fact, the use of EHR has been directly associated to clinician burn-out, as demonstrated by a number of studies. With new technologies such as Fujitsu’s latest AI text mining technology, we can address these challenges directly, and achieve tangible improvements to the clinical decision-making process.”
Fujitsu Laboratories of Europe’s Chief Executive Officer Dr Adel Rouz expands, “Our co-creation strategy with partners such as the San Carlos Clinical Hospital has provided us with an important insight into the challenges faced by the healthcare sector, particularly in terms of supporting clinical decision-making. We have succeeded in creating a number of important innovations that are already making a difference to medical professionals’ workflow. This latest advance is another step, helping to improve the accuracy of clinical data and automate its digitalization for hospitals, medical insurance companies and government agencies. We believe that our technology has wider applications and can easily be adapted to solve similar challenges in other domains, such as insurance, legal and compliance.”
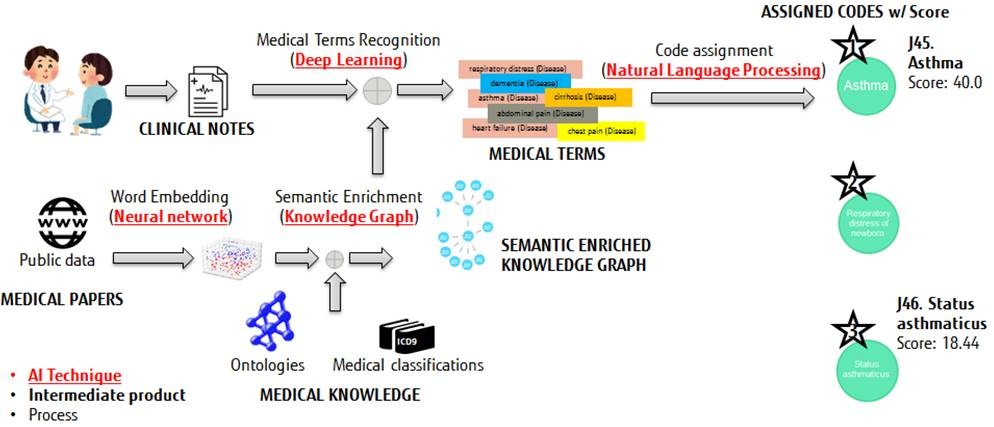
Structured information plays an essential role in medical decision-making and improving healthcare delivery. However, as clinicians are faced with significantly less direct patient time, the requirement for immediate data entry onto EHR systems represents a major additional burden. By enabling more flexible data entry methods, such as free text narrative associated with a patient report, this overhead can be reduced while also allowing clinicians to record more useful and appropriate patient data. Using its proven NLP techniques, Fujitsu Laboratories and Fujitsu Laboratories of Europe’s collaborated solution directly addresses this need, automatically extracting the structured information required by the EHR system from clinicians’ free narrative text. Using deep learning, the solution can be retrained to match a clinician’s individual needs, enabling additional flexibility compared to the limitations associated with complex linguistic rules used by many existing codification systems in order to identify the correct terms from the free text. The result is a high degree of accuracy, matched by the ability to extract a wider cross-section of relevant terms than just International Statistical Classification of Diseases and Related Health Problems (ICD) codes, relating to treatment adherence or social background data.
Fujitsu’s AI Text Mining healthcare solution exploits text mining together with Deep Learning techniques in concrete steps of the medical coding workflow, avoiding the dependency on huge pre-annotated datasets. Fujitsu’s approach comprises two key components:
- creation of the knowledge base: a knowledge graph is designed to depict the medical classifications and enriched semantically with external resources. This semantic enrichment provides additional context to medical classifications, translating into improved results in the successive stages of the process. Ontologies and word embedding techniques are used for the semantic enrichment.
- recognition and assignment: involving a medical terms‘ recognition process using Deep Learning, followed by the definition of weighted score-ranking formulas to calculate the potential encoding of input clinical notes.